سه شنبه, ۱۸ اردیبهشت, ۱۴۰۳ / 7 May, 2024
مجله ویستا
بهینهسازی درخواست کاربر مبتنی بر هوشمندسازی بازیابی اطلاعات
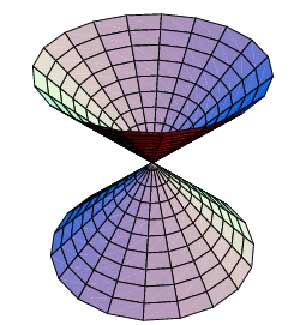
پس از آمادهسازی بردار درخواست، سیستم بازیابی اطلاعات با بكارگیری یك معیار مقایسه، بردار درخواست و بردارهای مدارك را مقایسه مینماید و نتیجه یك لیست ارزشگذاری۱۰ شده از مدارك شبیه به درخواست، بصورت نزولی براساس درجه شباهت خواهد بود. معیارهای مختلفی برای محاسبه شباهت مورد استفاده قرار میگیرد كه سادهترین آنها زاویه میان دوبردار است، بدین معنی كه هرچه زاویه میان بردارها (شكل۲) كمتر باشد، بردارها شبیهترند. بنابراین میتوان كسینوس زاویه میان دو بردار را محاسبه نمود و هرچه كسیسنوس به یك نزدیكتر باشد دو مدرك شبیهترند۳.
این روش در بسیاری از سیستمهای موجود كاربرد دارد، عیب این روش آنست كه بسیار به بردار درخواست وابسته است، به عبارت دیگر اگر بردار درخواست بخوبی بیان نشده باشد، آنگاه جوابهای سیستم بازیابی اطلاعات از دقت خوبی برخوردار نخواهد بود. باید دقت داشت كه كاربران سیستمهای بازیابی اطلاعات، همیشه افراد خبره۱۱ نیستند بنابراین سیستم باید بتواند درخواستهای ضعیف را با جایگزین كردن كلمات كلیدی تقویت كند و كاربر را در جهت ساخت درخواست مناسب راهنمایی نماید.برخی از سیستمهای هوشمند بازیابی اطلاعات، سعی بر آن دارند كه محتوای مدرك و درخواست را درك نمایند و یك رابطه میان درخواست و مدارك بوجود آورند. به عنوان مثال انتظار داریم سیستم هوشمند، درخواستهای “Clever Man” و “Bright Person” را یكسان بشمارد، و جوابهای یكسان برای آن استخراج نماید. این امر میسر نخواهد شد، مگر آنكه میان محتوای كلمات كلیدی و مدارك، ارتباط منطقی بوجود آید. در سیستم فعلی از این تئوری كه درخواستهای مشابه دارای جوابهای مشابه هستند استفاده خواهد شد.
در ادامه ابتدا مباحث مرتبط (بخش ۲) را بررسی خواهیم نمود، سپس یك روش هوشمند مبتنی بر شبكه عصبی (بخش ۳) مورد بررسی قرار خواهد گرفت.
● مباحث مرتبط
جهت بالا بردن كارآیی سیستمهای بازیابی اطلاعات، تلاشهای بسیاری انجام شده است، در زمینه ترمیم۱۲ بردار درخواست، روشهایی مبتنی بر سیستمهای فازی۱۳ و همچنین سیستمهمای دارای بازخورد۱۴ از انتخاب كاربر مورد استفاده قرار میگیرد. در سیستمهای فازی، مجموعه قوانین۱۵، به سیستم امكان انتخاب با عدم قطعیت میدهد. در چنین سیستمی قوانین در ابتدا استخراج میگردد و سپس در طول كار سیستم با توجه به بازخوردی كه از كاربر گرفته میشود، تغییر خواهد كرد. در این مقاله صرفاً كاربرد شبكه عصبی۱۶ در هوشمندسازی سیستم بازیابی اطلاعات مورد بررسی قرار میگیرد۴، ۵، ۶.● هوشمندسازی سیستم بازیابی اطلاعات
هدف این روش، تصحیح۱۷ بردار درخواست كاربر، با توجه دانش محلی۱۸ موجود در سیستم بازیابی اطلاعات است. شبكه عصبی را میتوان یك تابع غیرخطی۱۹ دانست كه وظیفه آن درونیابی۲۰ و یا برونیابی۲۱ است. این تابع میتواند با توجه به دانشی كه در مرحله آموزش۲۲ كسب نموده است، خروجی قابل قبولی در دامنه۲۳ ورودی مجاز داشته باشد. به عنوان مثال میتوان یك نقطه در درون و یا بیرون نقاطی كه در مرحله آموزش به شبكه داده شده است، محاسبه نمود. این نقطه با توجه به دانش موجود توسط تابع غیرخطی شبكه عصبی تخمین زده میشود. با توجه به عدم قطعیت۲۴ و ابهام۲۵ ذاتی موجود در سیستمهای بازیابی اطلاعات استفاده از سیستمی كه با بهرهگیری از دانش زمینه بتواند كاربر را در ساخت درخواست مناسب، راهنمایی نماید، ضروری به نظر میرسد. در حقیقت این سیستم مانند یك ناظر خبره، بر درخواستهای رسیده از كاربران نظارت مینماید و در صورت نیاز، با تصحیح بردار درخواست، كاربر را در بدست آوردن نتیجه مطلوب راهنمایی مینماید ]۱۲، ۱۳، ۸[.مطالعات اخیر در زمینه هوشمندسازی بازیابی اطلاعات، به این نتیجه رسیده است كه برای بهبود كارآیی سیستم بازیابی اطلاعات، احتیاج به تكنیكهایی است كه محتوای درخواستها و مدارك را درك كنند]۸[. اخیراً محققان تئوری اطلاعات سعی بر این داشتند كه رابطه میان مدارك و درخواستها را مشخص كنند ]۷، ۹، ۱۰، ۱۱[. هدف این است كه درخواست كاربر طوری تطبیق۲۶ پیدا كند كه اطلاعات مورد درخواست كاربر را در مجموعه محلی مدارك پیادهسازی نماید.پایه و اساس تطبیق درخواست این است كه درخواستهای مشابه دارای مجموعه مدركهای مشابه هستند. با استفاده از اطلاعات مدركهایی كه با درخواستهای قبلی مشابه بودهاند، میتوان مدارك مشابه با درخواستهای جدید را بدست آورد. تغییر شكل درخواست همانند شخص خبره عمل میكند]۱۲، ۱۳[. به عبارت دیگر سیستم ناظر شبكه عصبی حضور شخص خبره را شبیهسازی میكند. در شكل ۳ مدل كلاسیك (شكل ۳- ب)، با مدل هوشمند (شكل ۳- الف) مقایسه شده است سیستم هوشمند دارای مبدل درخواست T میباشد كه با توجه به دانش مجموعه، درخواست را بازسازی میكند.كاربرد این سیستم در مجموعه مداركی كه دستهبندی۲۷ شده باشند، بهتر نمایان میگردد. بدین صورت كه مثالهای آموزشی۲۸، براحتی و بطور خودكار، از شاخه۲۹های موجود در مجموعه استخراج میگردد. هر مثال آموزشی شامل چند كلمه كلیدی (درخواست) و مجموعه مدارك مرتبط با كلمات كلیدی است. سیستم هوشمند در دو فاز عملیات بازیابی را انجام میدهد. ابتدا مرحله یادگیری و آموزش ماشین۳۰ است، در این مرحله باید یك لیست از درخواستها (بردارهای درخواست) و جواب آنها (ماتریس مدارك جواب درخواست) به سیستم داده شود. در این مرحله سیستم شبكه عصبی دانش زمینهای مجموعه را كسب مینماید. فاز دوم، فاز بكارگیری و آزمایش سیستم هوشمند است، در این فاز سیستم هوشمند مانند ناظر، درخواستهای كاربر را پذیرفته و آنها را بهینهسازی میكند و سپس سیستم كلاسیك مانند قبل، بروی درخواست تغییر یافته، عملیات محاسبه شباهت را انجام میدهد. شكل ۴ سیستم هوشمند را در دو فاز یادگیری و بكارگیری نشان میدهد ۱۴، ۱۵
همانطور كه مشاهده میگردد سیستم از چهار قسمت تشكیل شده است:
۱) پردازشگر درخواست۳۱:
در این قسمت از سیستم، درخواست پردازش میگردد تا به بردار تبدیل گردد. در این مرحله از شاخص و وزندهی استفاده خواهد شد و یا ممكن است برای سرعت بیشتر از مدل منطقی استفاده شود. بنابراین خروجی این مرحله بردار درخواست است.
۲) پردازشگر مدرك۳۲:
این قطعه از سیستم، مدارك را مورد پردازش قرار میدهد و برای هر مدرك یك بردار از وزنها، ایجاد مینماید بنابراین خروجی این قطعه از سیستم، ماتریس كلمه-مدرك میباشد.
۳) مقایسهگر۳۳:
این قطعه از سیستم، بردار درخواست را با تمام بردارهای مدارك مقایسه مینماید، و یك لیست ارزشگذاری شده از مدارك شبیه را تهیه نموده به كاربر ارایه مینماید ]۱۴، ۱۵[.
۴) شبكه عصبی:
وظیفه شبكه عصبی تغییر بردار درخواست كاربر با توجه به دانش كسب شده، در مرحله آموزش میباشد. این بردار به عنوان خروجی این مرحله به مقایسهگر داده میشود.برای آنكه سیستم هوشمند بتواند بخوبی عمومیت بخشی۳۴ را در دانش مجموعه ایجاد نماید، مثالهایی كه جهت آموزش سیستم انتخاب میگردد، باید از تمامی دامنه مجموعه باشد. برای كارآیی بهتر میتوان، مدارك مجموعه را دستهبندی نمود و سپس از هر دسته مدارك شبیه، یك نماینده۳۵ كه عمومیت بیشتری دارد در آموزش شبكه عصبی شركت كند.در شكل ۵ نتیجه آزمایش این روش بروی مجموعه مدارك CranField مشاهده میگردد، در این نمودار نتیجه روش كلاسیك با روش هوشمند مقایسه میگردد. این مجموعه دارای ۱۴۰۰ مدرك و ۲۲۵ مثال آموزشی است. تعداد كلمات كلیدی كه در بیش از یك مدرك ظاهر شدهاند حدود ۴۴۰۰ كلمه میباشد.در عمل برای آموزش شبكه عصبی میتوان از فهرستهای موضوعی بیشترین بهره را برای، آموزش شبكه عصبی بدست آورد. بدلیل دستهبندی اطلاعات در این فهرستها، بهترین جواب در آموزش سیستم بدست خواهد آمد.
● نتیجهگیری
با مشاهده خروجی سیستم هوشمند به این نتیجه میرسیم كه سیستم هوشمند دارای كارآیی بالاترین نسبت به سیستم كلاسیك میباشد. این نتیجه با نظارت بر درخواست كاربر جواب بهتری را فراهم آورده است. زیرا بردار درخواست با دانش زمینه تطبیق داده شده و بهینهسازی میگردد، به عبارت دیگر سیستم هوشمند با درك معنای درخواست، در صورت نیاز آن را بهینهسازی مینماید.
مدل هوشمند برخی مشكلات مدلهای كلاسیك را حل كرده است:
▪ الزامی ندار كه درخواست ساختاری۳۶ مانند مدرك داشته باشد تابع مبدل T (شكل ۳) درخواست را پیكربندی۳۷ میكند، تا شباهت قابل محاسبه و سنجش باشد.
▪ كاربر ملزم نیست كه درخواست خود را به طور كامل، از محتوایی كه میخواهد بیان كند، تابع مبدلT، با استفاده از دانش محیط، درخواست را تغییر شكل خواهد داد، و درخواست را در فضای مدارك قرار خواهد داد.
▪ یك مدل هوشمند میتواند برای محاسبه شباهت استفاده شود، كه رابطه میان درخواستها با مدركهای مشابه را با استفاده از بازخورد كاربر مورد محاسبه قرار دهد. موقعیت مدرك در فضای مدارك، نسبت به تصمیم كاربر تغییر خواهد كرد.باید توجه كرد كه مدل هوشمند، در صورتی پاسخ مناسب و صحیح خواه داد كه در فاز آموزش با مثالهای جامع، یادگیری انجام شده باشد در غیر اینصورت ممكن است نتیجه مناسبی حاصل نگردد بنابراین پیشنهاد میگردد، كه سیستم هوشمند در صورتی مورد استفاده قرار گیرد، كه درخواست رسیده دارای تاریخچهای در زمان آموزش باشد، به عبارت دیگر در صورتی از سیستم هوشمند استفاده شود، كه درخواست دارای مثالهای مشابی در زمان آموزش باشد، در غیر اینصورت از سیستم كلاسیك بدون تغییر درخواست، استفاده گردد و بازخورد این درخواست مجدداً سیستم را تعلیم دهد. یعنی با توجه به انتخاب كاربر، میتوان با مجموعهای از مثالهای آموزشی سیستم را مجدداً تعلیم داد.
پینوشتها:
۱. Implement
۲.Document
۳.Query
۴.Indexing
۵.Format
۶.Vector Space Model
۷.Term Weighting
۸.Search Engine
۹.Boolean Model
۱۰.Rank
۱۱.Expert in domain
۱۲.Enhancing
۱۳.Fuzzy Logic Systems
۱۴.Feedback
۱۵.Rule base
۱۶.Neural Network
۱۷.Enhancing
۱۸.Background Knowledge
۱۹.Non linear Function
۲۰.Interpolation
۲۱.Extrapolation
۲۲.Learning
۲۳.Domain of input data (range of input)
۲۴.Uncertainty
۲۵.Vagueness
۲۶.Adapt
۲۷.Clustering
۲۸.Learning Samples
۲۹.Directroy
۳۰.Machine learning
۳۱.Query processor
۳۲.Document Processor
۳۳.Matcher
۳۴.Generalization
۳۵.Cluster Center
۳۶.Structure
۳۷.Configure
منابع
G. Salton. (۱۹۸۹)“Automatic text processing: the transformation, analysis and retrieval of information by computer”. Addison Wesley.
G. Salton. And McGill. (۱۹۸۳)“Introduction to modern information retrieval”, New York, Mc-GrawHill.
E. Chisholm. (۱۹۹۵)“New term weighing formulas for vector space method in information retrieval”, New York.
L. A. Zadeh, (۱۹۹۶)“Fuzzy Logic=Computing with Words”, IEEE Transactions of Fuzzy Systems, Vol.۴, No.۲, pp.۱۰۳-۱۱۱, May.
G. Salton and B. Buckley, (۱۹۸۸)“Term weighting approaches in automatic text retrieval”, IPM.
K. Sparck, (۱۹۷۲)“A statistical interpretation of term specificity and its application in retrieval”, Documentation.
R.K. Belew, (۱۹۸۹)“Adaptive information retrieval: using a connectionist representation to retrieve and learn about documents”, USA, June.
W.B. Croft. (۱۹۸۷)“Approaches to intelligent information retrieval”, IPM.
R.J. Brachman and D.L. McGuinness,(۱۹۸۸)“Knowledge representation, Connectionism, Conceptual Retrieval”, ACM SIGIR, France, June.
K.L. Kwok, (۱۹۹۰)“Application of neural network to information retrieval”, IEEE, P.۶۲۳-۶۲۶, USA.J.C. Scoltes, (۱۹۹۱)“Neural nets and their relevance for information retrieval”, Technical Report, Amsterdam.
K.J. Schmucher, Fuzzy set, (۱۹۹۰)“Natural Language Computations, and Risk Analysis”, W.H. Freeman and Company, translated by T.Onisawa, Keigaku Shuppan.
L.A. Zadeh, (۱۹۷۵)“The concept of Linguistic Variable and its Application to Approximate Reasoning (Part ۱)”, Information Sciences, ۸,pp.۱۹۹-۲۴۹.
R.S. Michalski, J.G. Carbonell, T.M. Mitchell (Eds.), (۱۹۸۳)“Machine Learning: An Artificial Intelligence Approach”, Springer-Verlag.
R.S. Michalski, J.G.Carbonell, T.M.Mitchell (Eds.), (۱۹۸۶)“Machine Learning: An Artificial Intelligence Approach”, Vol. II, Morgan Kaufman.
نوشته: محمدباقر دستغیب
عضو هیئت علمی كتابخانه منطقهای علوم و تكنولوژی شیراز
۱. Implement
۲.Document
۳.Query
۴.Indexing
۵.Format
۶.Vector Space Model
۷.Term Weighting
۸.Search Engine
۹.Boolean Model
۱۰.Rank
۱۱.Expert in domain
۱۲.Enhancing
۱۳.Fuzzy Logic Systems
۱۴.Feedback
۱۵.Rule base
۱۶.Neural Network
۱۷.Enhancing
۱۸.Background Knowledge
۱۹.Non linear Function
۲۰.Interpolation
۲۱.Extrapolation
۲۲.Learning
۲۳.Domain of input data (range of input)
۲۴.Uncertainty
۲۵.Vagueness
۲۶.Adapt
۲۷.Clustering
۲۸.Learning Samples
۲۹.Directroy
۳۰.Machine learning
۳۱.Query processor
۳۲.Document Processor
۳۳.Matcher
۳۴.Generalization
۳۵.Cluster Center
۳۶.Structure
۳۷.Configure
منابع
G. Salton. (۱۹۸۹)“Automatic text processing: the transformation, analysis and retrieval of information by computer”. Addison Wesley.
G. Salton. And McGill. (۱۹۸۳)“Introduction to modern information retrieval”, New York, Mc-GrawHill.
E. Chisholm. (۱۹۹۵)“New term weighing formulas for vector space method in information retrieval”, New York.
L. A. Zadeh, (۱۹۹۶)“Fuzzy Logic=Computing with Words”, IEEE Transactions of Fuzzy Systems, Vol.۴, No.۲, pp.۱۰۳-۱۱۱, May.
G. Salton and B. Buckley, (۱۹۸۸)“Term weighting approaches in automatic text retrieval”, IPM.
K. Sparck, (۱۹۷۲)“A statistical interpretation of term specificity and its application in retrieval”, Documentation.
R.K. Belew, (۱۹۸۹)“Adaptive information retrieval: using a connectionist representation to retrieve and learn about documents”, USA, June.
W.B. Croft. (۱۹۸۷)“Approaches to intelligent information retrieval”, IPM.
R.J. Brachman and D.L. McGuinness,(۱۹۸۸)“Knowledge representation, Connectionism, Conceptual Retrieval”, ACM SIGIR, France, June.
K.L. Kwok, (۱۹۹۰)“Application of neural network to information retrieval”, IEEE, P.۶۲۳-۶۲۶, USA.J.C. Scoltes, (۱۹۹۱)“Neural nets and their relevance for information retrieval”, Technical Report, Amsterdam.
K.J. Schmucher, Fuzzy set, (۱۹۹۰)“Natural Language Computations, and Risk Analysis”, W.H. Freeman and Company, translated by T.Onisawa, Keigaku Shuppan.
L.A. Zadeh, (۱۹۷۵)“The concept of Linguistic Variable and its Application to Approximate Reasoning (Part ۱)”, Information Sciences, ۸,pp.۱۹۹-۲۴۹.
R.S. Michalski, J.G. Carbonell, T.M. Mitchell (Eds.), (۱۹۸۳)“Machine Learning: An Artificial Intelligence Approach”, Springer-Verlag.
R.S. Michalski, J.G.Carbonell, T.M.Mitchell (Eds.), (۱۹۸۶)“Machine Learning: An Artificial Intelligence Approach”, Vol. II, Morgan Kaufman.
نوشته: محمدباقر دستغیب
عضو هیئت علمی كتابخانه منطقهای علوم و تكنولوژی شیراز
منبع : فصلنامه علوم اطلاع رسانی






















































































































































![بهترین گوشی ها برای تولید محتوا [اردیبهشت ۱۴۰۳] - زومیت](/news/u/2024-05-06/zoomit-ld09r.jpg)
















نمایندگی زیمنس ایران فروش PLC S71200/300/400/1500 | درایو …
دریافت خدمات پرستاری در منزل
pameranian.com
پیچ و مهره پارس سهند
تعمیر جک پارکینگ
خرید بلیط هواپیما
ایران آمریکا رافائل گروسی رهبر انقلاب دولت نیچروان بارزانی مجلس شورای اسلامی دولت سیزدهم انتخابات شورای نگهبان حسین امیرعبداللهیان رسانه
شهرداری تهران تهران قتل حجاب قوه قضاییه زنان سیل فضای مجازی آموزش و پرورش سلامت شهرداری سازمان هواشناسی
قیمت دلار قیمت خودرو خودرو بازار خودرو قیمت طلا ایران خودرو بانک مرکزی بورس سایپا دلار مسکن حقوق بازنشستگان
وزارت آموزش و پرورش نمایشگاه کتاب تلویزیون دفاع مقدس افعی تهران موسیقی تئاتر سریال سینمای ایران مسعود اسکویی سینما صدا و سیما
مایکروسافت دانشگاه آزاد اسلامی دانش بنیان فضا
رژیم صهیونیستی اسرائیل غزه حماس فلسطین جنگ غزه روسیه رفح چین طوفان الاقصی اوکراین نوار غزه
استقلال فوتبال پرسپولیس لیگ برتر ذوب آهن نساجی لیگ برتر ایران لیگ برتر فوتبال ایران بازی رئال مادرید سپاهان جواد نکونام
هوش مصنوعی زلزله اپل سامسونگ آیفون دوربین باتری گوگل ناسا تلفن همراه اندروید
بیماران خاص رژیم غذایی زیبایی بیمه کاهش وزن دندانپزشکی فشار خون سبزیجات