پنجشنبه, ۶ اردیبهشت, ۱۴۰۳ / 25 April, 2024
مجله ویستا
پردازش گفتار؛ مرور چند راهکار
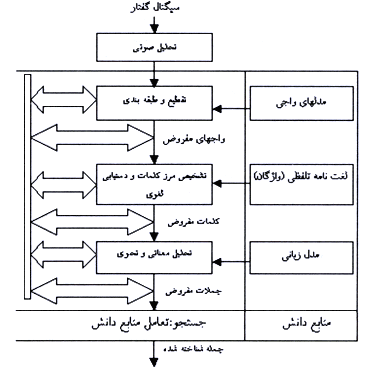
هدف بلندمدت سیستمهای بازشناسی خودکار گفتار، طراحی ماشینی است که سیگنال صوتی مربوط به یک جمله بیان شده را به دنبالهای از کلمات نوشته شده تبدیل نماید. سیستمهای بازشناسی خودکار گفتار اطلاعات متنوعی از منابع دانش گوناگون را در جهت دستیابی به جمله بیان شده از روی سیگنال صوتی دریافت شده، بهکار میگیرند.
اما مشکلات متعددی در بازشناسی گفتار پوسته بدون قید وجود دارد که عبارتند از:
۱. تحتتأثیر قرار گرفتن کیفیت سیگنال صوتی بهوسیله نویز محیط و تابع انتقال سیستم انتقال مانند میکروفون، تلفن و...،
۲. عدم وضوح مرز مابین کلمات و واجها در سیگنال صوتی،
۳. تنوع وسیع سرعت بیان،
۴. دقت ناکافی در بیان کلمات و بهخصوص انتهای آنها در گفتار محاورهای نسبت به گفتار مجزا.
۵. تأثیر تنوعات متعدد گوینده از جمله جنسیت، شرایط فیزیولوژیک و روانی بر گفتار،
۶. بهکارگیری محدودیتهای معنائی ـ نحوی زبان برای گفتار زبان طبیعی به روشی مشابه ارتباط انسان با انسان در سیستم بازشناسی.
در جهت غلبه بر مشکلات مذکور تاکنون روشهای متنوعی پیشنهاد شده است که از جمله آنها روشهای آماری مبتنی بر قانون تصمیمگیری بیز، روشهای مبتنی بر شبکه عصبی و در برخی موارد ترکیب روشهای آماری و شبکه عصبی است. با بررسی روشهای فوق میتوان دریافت که شناسائی کلمه یا واج بدون خطا بدون استفاده از دانش سطوح بالاتر بهخصوص در بازشناسی گفتار پیوسته با حجم لغتنامه بزرگ، امکانپذیر نیست. بهعنوان یک نتیجه، یک سیستم بازشناسی گفتار که با انبوهی از فرضها درباره واجها، کلمات و جملات مواجه است. در حالت ایدهآل بایستی محدودیتهای سطوح بالا را که بهوسیله واژگان، نحو، معانی و ادراک مشخص میشود، در نظر بگیرد. در سیستمهای مبتنی بر قانون تصمیمگیری بیز برخی از این محدودیتها توسط مدل زبانی به سیستم بازشناسی اعمال میشود.
نتایج مطالعات و بررسیها نشان داده است که مدلهای زبانی که در حالت کلی توالی واحدهای زبانی را مدل میکنند، در کاهش خطای بازشناسی نقش عمدهای ایفا میکنند. در این میان، استفاده از مدلهای زبانی مبتنی بر شبکههای عصبی با وجود قابلیت این شبکهها در یادگیری زنجیره نمادها و نیز بهدلیل قابلیت هموارسازی و خاصیت تعمیمدهی آنها بر روشهای آماری مزیت دارد.
● ضرورت انجام پروژه
باتوجه به کاربرد وسیع و روزافزون سیستمهای بازشناسی گفتار همواره نیاز به طراحی سیستمهائی با صحت بازشناسی بالا احساس میشود. این مسئله بهنوبه خود زمینههای تحقیقاتی فراوانی را باز کرده است که توجه پژوهشگران زیادی را به این شاخه جلب کرده است.
توجه به ساختار سلسله مراتبی گفتار در مغز انسان و پردازشهای دوطرفه در آن (تأثیر متقابل لایهها)، بنای مدلی با قابلیتهای سلسه مراتبی و پردازش دوطرفه جهت بهبود کیفیت بازشناسی تداعی مینماید. در ساختار مذکور توالیهای معتبر در هر لایه میتواند نقش تعیینکنندهای در شناسائی زنجیره ورودی در لایه پائینتر داشته باشد. مدلهای زبانی موجود از نگاهی دیگر به این مسئله توجه کردهاند و تأثیر مدل کردن توالی واحدهای زبانی، در بالا رفتن صحت بازشناسی را نشان دادهاند. در برخی پروژهها، هدف ارائه مدلهای زبانی در یک ساختار سلسله مراتبی و با الهام از سیستم درک گفتار انسان جهت بالا بردن صحت بازشناسی و تصحیح توالیهای بازشناسی شده است که در عین حال شیوههای کلیدی و مؤثر بیان شده توسط محققان دیگر را نیز در بر میگیرد.
● مروری بر کارهای انجام شده
مدلسازی آماری زبان:
مدلهای زبانی که به منظور بازشناسی گفتار و دیگر فنآوریهای زبانی بهکار برده میشوند، برای اولینبار در سال ۱۹۸۰ مطرح شدند. از آنزمان تاکنون تلاشهای فراوانی برای اصلاح و توسعه این مدلها به جهت کاربرد در سیستمهای پیشرفته امروزی صورت گرفته است. مدلهای آماری زبان توزیع احتمال واحدهای زبانی مختلفی مانند آواها، کلمات و جملات یک متن را محاسبه مینمایند.
مدلسازی زبان، تلاشی در جهت تسخیر قواعد زبان طبیعی به منظور بهبود کارآئی کاربردهای مختلف زبان طبیعی است. مدلهای زبانی برای کاربردهای مختلفی از فنآوری زبان از جمله بازشناسی گفتار، ترجمه ماشینی، طبقهبندی متون، بازشناخت نوری کاراکترها، بازشناسی دستنوشته و تصحیح هجا و... بهکار گرفته شدهاند.
بهعنوان نمونه در ترجمه ماشینی روشهای آماری محض و روشهای مبتنی بر قانون بهکار گرفته شدهاند.
مدلهای آماری زبان از روی دادگان متنی، پارامترهای بسیار زیادی را تخمین میزنند و بنابراین به حجم بالائی از دادگان تعلیم نیاز دارند. موفقترین فنآوری SLM دانش بسیار محدودی را از آنچه که یک زبان بهراستی است، در نظر میگیرد. مشهورترین مدلهای زبانی (N گرمها) واقعیتی را مدل میکنند که زبان نیست، بلکه دنبالهای از نمادها است و هیچ ساختار عمیقی ندارد.
در ادامه برخی از فنآوریهای بهروز SLM مرور میشود:
تقریباً تمامی مدلهای آماری زبان احتمال یک جمله را به حاصلضرب احتمالهای شرطی تجزیه مینمایند.
مدلهای N گرم
N گرمها یکی از مشهورترین مدلهای آماری زبان هستند. در این مدلها با بزرگتر شدن N با وجود در نظر گرفته شدن ارتباطات بلندمدت زنجیره کلمات، مشکل نیاز به حجم بالای دادگان تعلیم جهت آموزش مدل بهوجود میآید. بسیاری از زنجیرههای مهم در دادگان تعلیم یا یکبار یا به دفعات کمی اتفاق میافتند. بنابراین تخمین احتمالهای N گرمها بهوسیله شمارش تعداد دفعات وقوع یک زنجیره صورت میگیرد، روش مناسبی نیست. برای رفع این نقیصه، روشهای هموارسازی متعددی تهیه و توسعه داده شدهاند.
از جمله این روشها میتوان به موارد زیر اشاره کرد:
۱. نزول به N گرمهای مرتبه پائینتر بهصورت بازگشتی.
۲. درونیابی خطی N گرمها.
۳. استفاده از N گرمهای با طول متغیر.
مدلهای درخت تصمیم:
الگوریتمهای درخت تصمیم اولینبار برای مدلسازی زبانی بهکار گرفته شد.
مدلهای با انگیزه زبانی:
با وجود آنکه تمام SLMها از ذات زبان الهام میگیرند، ولی در بیشتر این مدلها محتوی زبانی نادیده انگاشته میشوند. در این میان برخی از مدلهای SLM بهصورت مستقیم از روی دستور زبانی که بهصورت معمول توسط زبانشناسها بهکار گرفته میشود، بهدست میآید که از این دسته دستور زبان مستقل از محتوی و گرامر متصل را میتوان نام برد.
مدلهای نمائی:
تمامی مدلهائی که تاکنون بررسی شدهاند، از این مشکل که مدلسازی با جزئیات بیشتر، کاهش دادگان برای پارامترهای جدید را به همراه دارد، رنج میبرند.
مدلهای تطبیقی:
در مدلهائی که تاکنون ذکر شد، زبان یک منبع همگن فرض شده است. ولی در واقعیت زبان بسیار غیرهمگن است. در تطبیق تقاطع دامنه، دادگان تست از منبعی بهغیر از منبعی که در طول تعلیم مدل زبانی از روی آن بهدست آمده، هستند.
در تطبیق درون دامنه دادگان تست از همان منبع تعلیم مدل زبانی هستند، اما این منبع غیرهمگن است.
تطبیق در چنین مواردی بهصورت زیر انجام میگیرد:
۱. پیکره تعلیم براساس بعد تنوع دستهبندی میشود.
۲. در هنگام اجراء بر روی دادگان تست، موضوع شناسائی میشود.
۳. مجموعه موردنظر از دادگان تعلیم، برای ساختن مدل مشخصی بهکار گرفته میشود.
۴. مدل جدید با مدل قبلی، بهوسیله درونیابی خطی ترکیب میشود.
● مدلهای زبانی اتصالگرا:
در سال ۱۹۸۹ ناکامورا و شیکانو بهصورت تجربی نشان دادهاند که چگونه یک پرسپترون چندلایه میتواند قابلیت پیشبینی مدل سه گرم به انضمام قابلیتهای بهتر تعمیمدهی را شبیهسازی نماید. در کار دیگری برای غلبه بر دو مشکل اساسی مدلهای N گرم یعنی:
۱. کوچک بودن N سبب میشود تا ارتباطات بلندمدت واحدهای زبانی در نظر گرفته نشود.
۲. بزرگ شدن N، حتی در مدل سه گرم سبب میشود تا احتمالات تخمینزده شده، به خاطر اینکه بسیاری از ترکیبات اتفاق نمیافتد یا کمتر اتفاق میافتد، قابل اعتماد نباشد.
یک شبکه عصبی پرسپترون با دو لایه پنهان به نام NETGram برای استخراج مدل زبانی دو گرم، سه گرم و چهارگرم بهکار گرفته شده است. در این روش با دستهبندی کلمات در قالب بخش نحوی، نیاز به حجم بالای دادگان برای تعلیم شبکه حل شده است. از مزایای مدل مذکور و در حالت کلی مدلهای زبانی اتصالگرا نسبت به مدلهای زبانی آماری، افزایش خطی پارامترها با افزایش N در مدلهای زبانی اتصالگرا در مقایسه با افزایش نمائی آنها در مدلهای زبانی آماری است. مزیت دیگر این مدلها آن است که در مدلهای زبانی اتصالگرا هموارسازی بهصورت مستقیم توسط خود مدل اجراء میشود.
در گزارش دیگری در این رابطه که توسط یک شبکه عصبی تمام متصل نشان داده شده، مدل زبانی N گرم پیادهسازی شده است. این شبکه از دو لایه پنهان، یک لایه تصویر و یک لایه پنهان تشکیل شده است.
علاوه بر شبکههای زمانی مذکور، شبکههای عصبی بازگشتی برای یادگیری زبانهای با قاعده از مجموعه رشته مثالها و مثالهای نقض بهکار گرفته شدهاند. این شبکهها به این دلیل که میتوانند که شناساگرهای زبانهای با قاعده را شبیهسازی نمایند، در پردازش زبان طبیعی بسیار رایج و متداول هستند. بهعنوان مثال از کاربردهای دیگر شبکههای عصبی بازگشتی میتوان به مدلسازی زنجیره نمادها توسط این شبکهها اشاره کرد. نتایج بررسی نشان میدهند که شبکههای عصبی بازگشتی در کار با دنبالههای حاصل از یک ماشین حالت محدود یا حتی آشوبگونه نتایج قابل قبولی داشتهاند. استفاده از شبکههای عصبی بازگشتی و چندلایه در طبقهبندی معنائی و نحوی کلمات چینی با حجم دادگان بزرگ و نیز استنتاجهای دستور زبانی جملات نتایج قابل توجهی داشته است.
استفاده از مدلهای زبانی نه تنها در سطح کلمه، بلکه در سطح آوا نیز کاملاً رایج است. هاوس و نئوبرگ نشان دادند که محدودیتهای موجود روی زنجیره آواها بهعنوان روش مؤثری در شناسائی میتواند بهکار گرفته شود.
در کار انجام شده، نشان داده شد که این محدودیتها بهعنوان مشخصهای قدرتمند در بازشناسی گفتار، حتی در مواردی که گفتار به بخشهای متنوعی تعلق دارد، میتواند مورد استفاده قرار گیرد.
دکتر محمدرضا یزدچی
دکتر سیدعلی سیدصالحی
دکتر سیدعلی سیدصالحی
منبع : ماهنامه تخصصی مهندسی پزشکی




همچنین مشاهده کنید




































































































نمایندگی زیمنس ایران فروش PLC S71200/300/400/1500 | درایو …
دریافت خدمات پرستاری در منزل
pameranian.com
پیچ و مهره پارس سهند
خرید میز و صندلی اداری
خرید بلیط هواپیما
گیت کنترل تردد
ایران سریلانکا حجاب کارگران رهبر انقلاب مجلس شورای اسلامی پاکستان رئیسی سید ابراهیم رئیسی رئیس جمهور دولت سیزدهم مجلس
فضای مجازی کنکور سیل شهرداری تهران تهران هواشناسی پلیس سلامت فراجا قتل وزارت بهداشت زنان
خودرو تورم قیمت خودرو قیمت دلار قیمت طلا دلار بانک مرکزی بازار خودرو ایران خودرو سایپا بورس قیمت سکه
ترانه علیدوستی تلویزیون سریال کتاب سینمای ایران تئاتر سینما انقلاب اسلامی شعر
کنکور ۱۴۰۳ دانشگاه فرهنگیان
اسرائیل رژیم صهیونیستی آمریکا غزه فلسطین روسیه جنگ غزه چین طوفان الاقصی ترکیه عملیات وعده صادق اتحادیه اروپا
فوتبال پرسپولیس استقلال فوتسال بازی باشگاه پرسپولیس باشگاه استقلال تراکتور تیم ملی فوتسال ایران بارسلونا رئال مادرید لیگ برتر
فیلترینگ تسلا تبلیغات همراه اول ایلان ماسک ناسا فناوری اپل نخبگان
سلامت روان دوش گرفتن یبوست